DeepSeek Computing Cluster Hardware Architecture
- Overall Configuration: A large-scale computing cluster equipped with 2048 NVIDIA H800 GPUs.
- Node Configuration: Each computing node contains 8 GPUs.
Node-to-Node Communication: High-speed interconnection via NVLink and NVSwitch.
Inter-node Communication: Efficient communication using InfiniBand (IB) technology.

Learning Algorithm Used by DeepSeek
DeepSeek utilizes the Group Relative Policy Optimization (GRPO) algorithm, an efficient reinforcement learning algorithm that optimizes the model’s strategy by comparing different answers to the same problem. The core idea of GRPO is to sample a set of outputs, calculate their rewards, and update the model’s parameters based on the relative value of the rewards.
How DeepSeek Was Trained
Training Method for the Original DeepSeek-R1-Zero Model
DeepSeek-R1-Zero was trained using pure reinforcement learning (RL) directly on the base model (DeepSeek-V3), without the need for supervised fine-tuning (SFT) as a preprocessing step—thus skipping the manual data annotation phase. DeepSeek-R1-Zero’s performance was comparable to OpenAI-o1-0912, marking the first validation of pure RL driving the evolution of LLM reasoning abilities (DEEPSEEK-R1-ZERO), providing a new paradigm for model optimization in unsupervised settings. Although DeepSeek-R1-Zero excelled in reasoning tasks, it had some issues with language expression and readability:
1. Language Mixing: The model could mix multiple languages during the reasoning process, making the output difficult to understand.
2. Formatting Issues: The model’s output might lack clear formatting, such as missing highlighted answers or summaries.
Training Method for the Latest DeepSeek-R1 Model
To address the issues of language expression and readability, the authors introduced the DeepSeek-R1 model, employing more advanced training methods. This approach involved four key training steps:
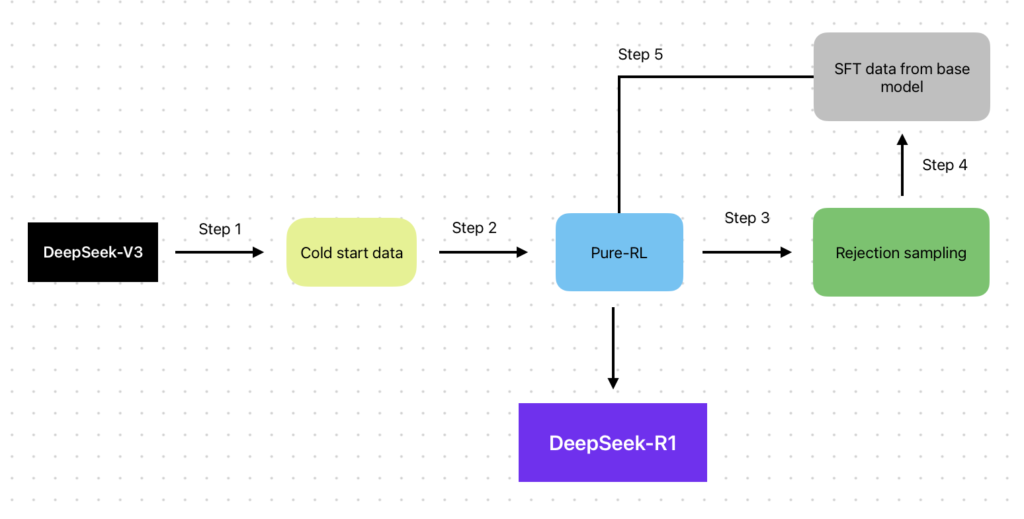
- Inference-Oriented Cold Start Data
Cold start data was collected by gathering a small amount of long inference chains (CoT) to fine-tune the base model. This data not only enhanced the model’s reasoning ability but also improved output readability. The authors used various methods to collect cold start data, such as using a small number of sample prompts and directly prompting the model to generate detailed answers. - Inference-Oriented Reinforcement Learning
After fine-tuning with cold start data, DeepSeek-R1 continued with reinforcement learning training similar to DeepSeek-R1-Zero. During this phase, the authors introduced a language consistency reward to reduce the language mixing problem during reasoning. - Full-Scene Rejection Sampling and Supervised Fine-Tuning
As reinforcement learning neared convergence, the authors generated new supervised fine-tuning data through rejection sampling and incorporated data from other domains (such as writing, factual Q&A, etc.) to further fine-tune the model. This step aimed to improve the model’s performance on non-reasoning tasks. - Full-Scene Reinforcement Learning
Finally, DeepSeek-R1 underwent a second phase of reinforcement learning, combining reward signals from both reasoning tasks and non-reasoning tasks to further enhance the model’s generality and safety.
How DeepSeek Reduce Cost
The pre-training cost for DeepSeek-V3, as disclosed in the technical report, is approximately $5.5 million, not including the expenses for initial exploration of model architecture, ablation experiments, and other related costs. This is based on a rental cost of $2 per hour per H800 GPU. The training efficiency has been improved through optimizations in four key areas: load balancing, communication, memory, and computation, which in turn helped save on costs.
Load Balancing Optimization
DeepSeek uses the MLA and MoE architecture to train an extremely large model. The biggest challenge here is load balancing. To address this, the DeepSeek team innovatively proposed a strategy called Auxiliary-Loss-Free Load Balancing, where a bias is added to the expert selection process when calculating which expert a token will be routed to. The core of the bias is to ensure that the load across experts is balanced. If this is achieved, it can improve the overall cluster efficiency. There was a paper published in August 2024 on this, and the bias only affects the routing of experts without influencing the gradient. The bias is dynamically adjusted with the following simple strategy: If an expert is overloaded, the bias is reduced; if an expert has insufficient load, the bias is increased. The key is to maintain balance across the experts. If expert load balancing is not well controlled, improving utilization during large-scale cluster training becomes difficult.
Communication Optimization
Using expert parallelism introduces significant All-to-All communication overhead. To reduce this overhead, DeepSeek devised several methods. One of them is the DualPipe algorithm, which carefully schedules computation and communication. Additionally, they implemented a design in the code that limits cross-node token routing, restricting each token to route to no more than four physical nodes. This is essentially an algorithmic adjustment to manage communication efficiently.
Memory Optimization
Memory is crucial in large model training. The DeepSeek team explored many approaches to optimize memory usage. For example, they proposed a method to recompute certain operations, where some forward calculations are not stored and are instead computed during the backward pass, which saves memory. They also moved some data, such as model parameter exponential moving averages, to CPU memory, further reducing GPU memory usage.
Computation Optimization
To improve model accuracy, DeepSeek employs MTP (Model Training Parallelism). They deploy the main model and MTP module’s output head and embeddings on the same node, allowing parameter sharing. The core goal here is to reduce memory usage. DeepSeek has not disclosed the number of nodes used for training, but for a given computational capacity, GPU memory is a valuable resource.
Furthermore, to enhance training efficiency, DeepSeek uses mixed precision, employing NVIDIA’s latest FP8 format. They use FP8 for major computational tasks, like large matrix multiplications. However, using low precision for training may lead to non-convergence or the presence of outliers in activations or weights.
To mitigate the impact of these outliers, DeepSeek explored several methods. They implemented fine-grained quantization, with tail-strip grouping quantization for activations and block-grouping for weights. They also increased accumulation precision (FP32), added more tail elements, and adopted an online quantization strategy. These techniques are aimed at reducing the impact of outliers, improving model accuracy. Ultimately, they achieved model convergence using FP8 precision.
How DeepSeek Changes The LLM Story
DeepSeek demonstrates how reinforcement learning can enhance LLMs’ reasoning capabilities and transfer these abilities to smaller models through knowledge distillation. This research provides crucial insights for the future development of smarter, more efficient LLMs. The significance of the study can be summarized as follows:
- Methodological Innovation: It marks the first validation that pure RL can drive the evolution of LLM reasoning capabilities (DEEPSEEK-R1-ZERO), providing a new paradigm for model optimization in unsupervised settings.
- Engineering Value: The design of a multi-stage training pipeline (DEEPSEEK-R1) that balances performance and readability, offering an efficient solution for the industry. It also demonstrates that large model reasoning patterns can be transferred to smaller models via distillation (DEEPSEEK-R1-Distill), reducing deployment costs.
- Community Contribution: The model is open-source with accessible technical documentation, promoting the reproducibility of slow-thinking reasoning research and broadening the accessibility of the technology.
- Opened up new directions for the next phase of AI: DeepSeek has significantly reduced the cost of model training through technological innovation, demonstrating that AI development does not necessarily require vast amounts of funding and computational power. This has opened up new directions for the next phase of AI industry development.
References:
https://arxiv.org/pdf/2501.12948
https://zhuanlan.zhihu.com/p/20844750193
https://deepseek.csdn.net/67b2a4fdc8869b4726b68ba6.html
https://36kr.com/p/3152872354814728










